网络药理学常用数据库汇总
大家好,现在给大家汇总一下网络药理学常用的一些数据库。
先说明以下 4 点:
(1)目前有不少人都在建设各类医药数据库,所以数据库是层出不穷的,不要过于纠结或者恨不得把所有数据库都学一遍;
(2)一些同学在面对新的数据库会感到畏惧,不会操作,其实都可以自己百度或者检索相关教程,百度没有就谷歌检索。另外一般大数据库都有自己发表的文章,也有自己的网站介绍,仔细读读看看,大胆操作,数据库点错了又不会损失什么;
(3)一些网站有时候打不开或者一直打不开很正常。要知道一些网站需要维护,暂时会关闭一段时间。或者一些人做数据库就是为了发文章,文章发完也不维护网站了。也有可能就是项目凉了。一个数据库用不了换一个就行;
(4)数据库肯定还会有新的,这里汇总不保证全,但我尽量搜集全,如果这里有不足之处,大家可以一起补充的。我也可以再出新的一期专栏。
一:中药数据库汇总
主要是用于获取中药成分的,有些数据库包含了其靶点。
1. TCMSP
https://tcmsp-e.com/ (网址 1);old.tcmsp-e.com/tcmsp.php (网址 2)https://tcmsp-e.com/(网址 3) 打不开的话就换老版网站,还打不开换个浏览器试试
2. ETCM
3. HERB
http://herb.ac.cn/ (包含动物、矿物药)
4. BATMAN-TCM
http://bionet.ncpsb.org/batman-tcm/
5. TCMID
http://www.megabionet.org/tcmid/(包含**动物、矿物药**,无靶点信息)
6. SymMap
https://www.bioinfo.org/symmap (中医证候与西医疾病病的对应,个人感觉这一块非常一般)
7. NPASS
http://bidd2.nus.edu.sg/NPASS (包含动物药)
8. YaTCM
http://cadd.pharmacy.nankai.edu.cn/yatcm/home (目前打不开)
9. TCM-MESH
http://mesh.tcm.microbioinformatics.org/ (目前打不开)
10. TCM-ID
http://bidd.nus.edu.sg/group/TCMsite/Default.aspx(无靶点信息)
11. TCM@Taiwan: TCM Database@Taiwan
http://tcm.cmu.edu.tw(老早以前打不开,现在能打开)
12. HIT: Herbal Ingredients‘ Targets Database Introduction
http://lifecenter.biosino.org/hit/ (以前能打开,目前打不开)
13. 化学专业数据库
http://www.organchem.csdb.cn/scdb/default.htm(需要寻找中药材)
14. 抗肿瘤天然产物数据库
15. HIT 数据库
16. 中药免疫肿瘤学数据库
二、获取化合物信息的数据库
有时候需要搜集中药化合物的各种信息如 ADMET 信息 (T 为毒性),一些网站也整理了化合的靶标,类似的网站很多
1. Pubchem (美国国家生物信息中心)
https://pubchem.ncbi.nlm.nih.gov/
2. Swiss ADME (主要是预测)
3. 中科院化合物参考数据库
http://www.chemcpd.csdb.cn/cmpref/default.asp (既有中药与有效成分数据,也有 ADMET 预测功能)
4. ProTox-II - Prediction of TOXicity of chemicals (charite.de)
https://tox-new.charite.de/protox_II/ (专门预测化合物毒性的数据库)
5. ChEMBL 药物化学数据库
http://www.ebi.ac.uk/chembl(也能预测靶标,但比较有限)
6. DrugCentral 数据库
7. STITCH 数据库
http://stitch.embl.de/ (预测化合物与蛋白结合)
8. PharmMapper
http://lilab-ecust.cn/pharmmapper/ (预测化合物与蛋白结合)
…… 挺多的,就不一一列举了。
一些中药数据库自带化合物的 ADME 属性信息,如 TCMSP , ETCM 等,自己可以多注意。
三、疾病数据库汇总
主要是用于收集疾病相关靶点的。
1. GeneCards
2. OMIM
3. Drugbank
https://go.Drugbank.com/(一个大型综合数据库,化合物,疾病靶点,适应症,比较丰富,归在这里可能不合适)
4. TTD
5. DisGeNET
6. GEO
7. TCGA**(这俩网址不放了,太常见了)**
8. GEPIA
8. Malacards****
还有就是一些专病数据库了,包括心血管、肿瘤学、抑郁症、环境毒物遗传数据库就不展开说了。
四、生物信息学相关数据库 / 平台
大家应该都知道的
1. 蛋白质数据库:
2. 蛋白质互作 STRING 数据库
https://www.string-db.org/ (蛋白质互作数据库有好几个,但这个默认是用得最多的)
其他数据库可以自己检索一下,另外 Cytoscape 软件里的 Bisogenet 集成了 DIP,BIOGRID,HPRD,BIND,MINT 和 INTACT 蛋白互作数据库。
3. DAVID
4. Metascape
https://metascape.org/ (最推荐的)
5. FunRich
6. KEGG
一般可以用于查通路,画信号通路用,总之比较综合。
7. Reactome
本文来源:https://www.jianshu.com/p/21244a67e3d1
UniProt 数据库——蛋白质数据库
**UniProt(Universal Protein)数据库是信息最丰富、资源最广的蛋白质数据库。常用的是 UniProtKB,它是收集蛋白质功能信息的中心枢纽,拥有准确、一致和丰富的注释。除了为每个 UniProt 条目捕获必须的核心数据(主要是氨基酸序列、蛋白质名称或描述、分类数据和引文信息),还添加了尽可能多的主食信息。
**
**UniProtKB/Swiss-Prot:高质量的、注释的、非冗余的数据集,这些数据都是有质量保证的。
**
**UniProtKB/TrEMBL:该数据集高质量的计算分析结果,需要我们手工注释。
**
Entry:是 Uniprot 给每个蛋白质赋予的独一无二的 ID
Entry name:是蛋白 ID 的简要名字
Protein names:蛋白质的名字
Gene names:编码这个蛋白的 Gene 名字
Organism:蛋白质的种属来源
Length:氨基酸长度
**详细信息界面,首先介绍的是「Function」,该板块会罗列出蛋白的基本功能及参与的生物学过程,这应该也是科研人员最关心的问题,具体的序列和结构只是为了方便研究或者更加深入理解蛋白的功能。每句介绍后的链接即是相应的参考文献( Publications),可以根据需要点击查阅。“By similarity” 链接到最相似的蛋白,往往是不同种属中的相同蛋白,也就是同源蛋白(直系同源基因是同源基因,进化后分化形成不同的物种,这种现象被称为物种形成。这些基因通常与它们进化而来的祖先基因保持着相似的功能)。很多蛋白在进化过程中是高度保守的,也就是说他们的蛋白序列非常相似或者相同,这一类蛋白往往有非常强大的功能,参与多种生命活动或生物学功能。
**
命名和来源种属信息:(Name&Taxonomy)板块展示的是该蛋白的名称(基因名称、同义词)和来源种属信息以及 NCBI 和 Enzembl 的基因数据库链接。
亚定位(Subcellular location)包含蛋白的细胞亚定位信息。
翻译后修饰:在(PTM/Processing)部分,UniProt 数据库会列举蛋白合成过程中的分子加工、氨基酸修饰及翻译后修饰,比如剪切、糖基化等。修饰过后的蛋白质分子质量就会增加。这也是为什么有些抗体的实际检测分子量和预测分子量有差别的原因之一。
**GeneCards 基因名片数据库(https://www.genecards.org/)GeneCards 由非盈利组织构建的一个整合型的生物信息数据库,该数据库提供了人力目前已注释的、可预测的所有基因的详细信息,并自动集成了来自约 150 个数据源的以基因为中心的数据,包括基因组、转录组、蛋白质组、遗传学、临床和功能信息。
**
**OMIM(Online Mendelian Inheritance in Man)数据库,中文称在线人类孟德尔遗传数据库。OMIM 侧重于疾病表型与其致病基因之间的关联。
**
需要注意的是:这个网站是于研究和教育的,注册需要正式邮箱(我用学校邮箱注册的)。如果 Gmail,Yahoo,http://126.com,http://163.com 或 http://qq.com 的电子邮件地址将被网站自动拒绝。
**OMIM 数据库包括 1.gene entry 基因条目;2.allelic variations 等位基因变异;3.gene map 基因图谱;4.phenotypic series 表型系列;5.phenotype entry 表型条目;6.clinical synopsis 临床提要;7.external links 外部链接
**
首先在搜索条中搜索某个疾病或者基因,双击高亮链接(也就是包含关键词的目的链接),会出现一个界面。
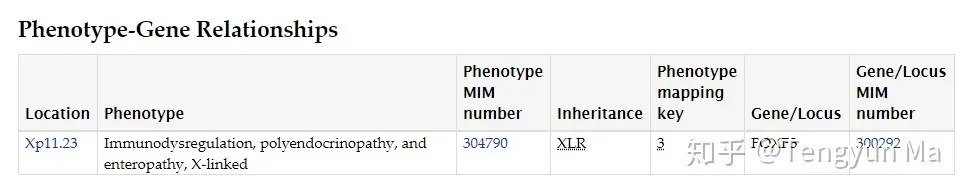
location 代表相关基因在染色体中的位置;phenotype 代表基因相关的表型;phenotype MIM number 代表表型的 MIM 编号;inheritance 代表遗传,是指该基因的遗传类型,如 AD 是指常染色体显性遗传,SMu 是指体细胞突变,鼠标点击缩写符号就会出现不同缩写代表的具体含义;phenotype mapping key 代表表型映射关键,3 代表该疾病的分子基础是已知的;Gene/Locus 代表对应的基因或位点;Gene/Locus MIM number 代表对应的基因或基因座 MIM 编号。点 location 还能显示该位置在同一个染色体相邻的基因列表以及引发的各种疾病.
OMIM 与其说它是个数据库,不如说它是个工具书,它能够让你从基因到 DNA 到染色体到蛋白质到表型全方位的去认识一个疾病。
**DisGeNET 数据库(http://www.disgenet.org/home/)
**
人类疾病遗传的基础是精准医学和药物发现的核心。数据的可用性、碎片化、异构性和概念描述的不一致是疾病机制研究必须克服的问题。DisGeNET 收集了大量与人类疾病相关的变异和基因。DisGeNET 整合了公共数据库、GWAS 目录、动物模型和科学文献的数据。该数据库的数据采用了统一的标准进行注释。此外,还提供了一些原始指标,以帮助确定基因型与表型关系的优先级。可以通过 web 接口,Cytoscape 应用程序(插件)、R 访问这些信息。DisGeNET 是一个多功能平台,可用于不同的研究目的包括特定的人类疾病的分子基础及其并发症的研究,致病基因特性分析,辅助构建药物治疗作用及药物不良反应假说,疾病候选基因的验证及文本挖掘方法的评价性能。
**R Package :
**
在 R 上安装 disgenet2r 包后后既可以进行 DisGeNET 数据库搜索,也可以进行可视化。但值得注意的是该 R 包目前的基于 DisGeNET v5.0 (May, 2017)。安装和使用示例如下:
安装:
**##**The package,disgenet2rcan be installed usingdevtoolsfrom this repository:
library(devtools)
install_bitbucket("ibi_group/disgenet2r")
数据库检索示例:
**##**以基因为检索词进行检索
library(disgenet2r)
gq**<-disgenetGene(gene=**3953,
database**=**"ALL",
score**=**c(">",0.1))
**##**以疾病为检索词进行检索
library(disgenet2r)
dq**<-disgenetDisease(disease=**"umls:C0028754",
database**=**"ALL",
score**=**c('>',0.3))
3.Cytoscape App****:
安装:
需要预装 Cytoscape,然后直接在 Cytoscape 安装 DisGeNET 插件。
Cytoscape App 主要功能就是将 DisGeNET 的数据用 networks 的形式进行展示,主要包括以下几个方面:
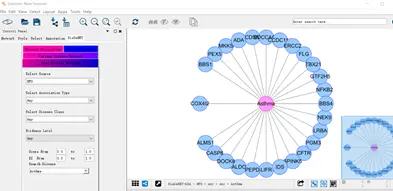
a) Generate gene-disease networks:即基因和疾病间 networks,例如 HPO 数据库中 Asthma 基因和疾病间 networks 示例如下:
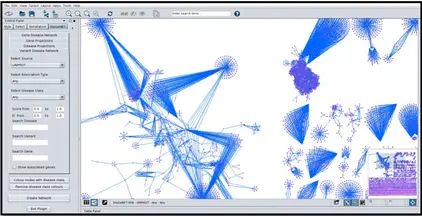
b) Generate variant-disease networks:即变异和疾病间 networks,示例如下
c) Generate gene or disease projection networks:即基因 - 基因间或者疾病 - 疾病间的 networks,示例如下
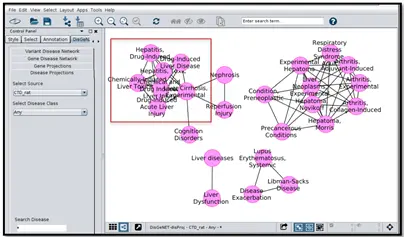
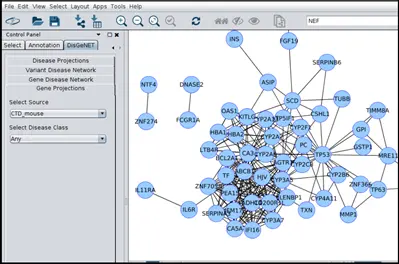
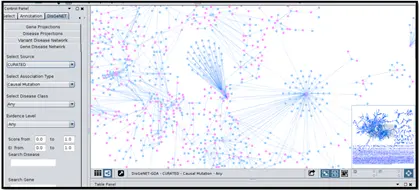
d) Create networks by DisGeNET association type:即检索某一关联关系,并将其可视化,如下面的 The CURATED GDA network for CausalMutations
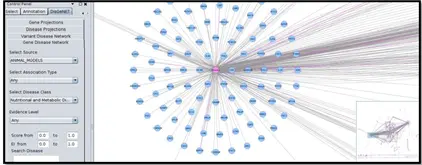
e) Create networks by disease class:对某一类疾病建立 network,如下是营养代谢病 network
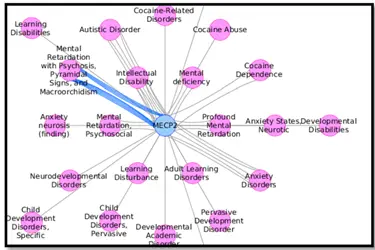
f) Create networks by gene, disease, or variant:可以不限制具体哪两个(基因、变异、疾病)间的关系,而是通过过滤条件得到 network,例如可以从以下几方面进行过滤:Source, Association Type,Disease Class, Score。下面是以 MECP 为检索词,过滤条件为 Mental Disorders 时构建的网络
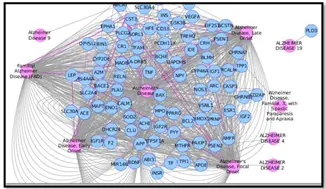
g) Multiple entity search in the DisGeNET App:包括匹配某一关键字的疾病或者基因的元素间构建网络、基于基因 / 变异列表构建网络。如下图是 CTD 数据库中 Alzheimer 相关的基因,包含了 Alzheimer 的所有亚型。
DisGeNET 部分作者:bioyangyang